Maps in Golang have a very delicate drawback: As soon as you try to write on them while other reads are reading or writing on it, your program will crash.
This is especially cruel because these errors occur only as race conditions, so you can test on your test server and everything works. As soon as you enter production, crashes can occur and you will have debug them. Luckily, go’s backtrace will give you very precise hints where to fix your code.
However, there are lots of competing implementations on concurrent maps in Go. Github is full of them. But they all have one thing in common: They use locks.
The problem with locks is, that even in a read-only scenario, all reading parties need exclusive write access to a memory page, so whenever you read a lot from that map, this will become your memory bottleneck.
I worked on a completely bottleneck-free implementation of maps in go:
https://github.com/launix-de/NonLockingReadMap
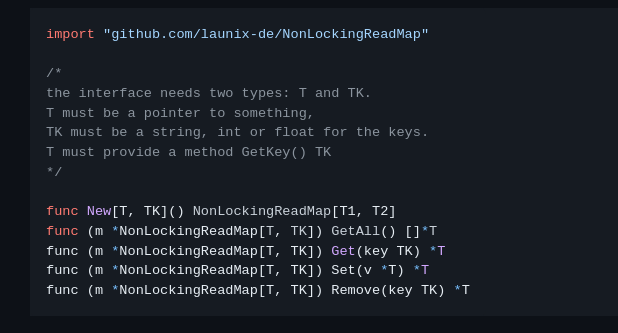
How it works
It comes with great performance and scalability, but also has one drawback: Write is expensive. But how does the library achieve that non-blocking fully parallel nature?
The map itself is stored as a pointer to an ordered array of pointers. Scanning an ordered array for a certain item takes O(log(N)) – however reordering the whole list takes O(N*log(N)). The scan itself is rather efficient since it works on dense pointers and is thus more cache friendly than a hash map and also more efficient than a simple array map (like PHP uses for associative arrays).
The magic lies behind the scenes: The library uses Golangs atomic package (https://pkg.go.dev/sync/atomic). But what is atomic compare-and-swap and when should we use it?
Atomic compare and swap is a builtin function available in most modern CPUs and allows for atomically exchanging a pointer-aligned pointer-sized value across a SMP system. So it is a function that reads from a memory location, returns the old value and at the same time saves a new value there.
To build a threadsafe data structure, the following algorithm has to be implemented:
- Read the old value from the memory location
- Compute and Manipulate something (e.g. create a new pointer with a copied+manipulated data structure)
- Atomically compare&swap the new value with the old one
- The atomic operation compare the two old values with each other and only writes the target value if the old values had stayed the same
- If the old values are unequal, someone else has worked on the value concurrently, so we have to start again at step 1
As you see, the operation is rather efficient when we are the only ones who write on the data. However, as soon as someone else is writing, too, the operation becomes costly because we can redo all our operations and hope that the underlying data did not change this time. A comfort is that at least one write will always come through, so as long as the amount of total writes does not increase over time, there is a finite amount of time after which all writes will be completed even if there are lots of concurrent writes at the same time.
This kind of parallelization technique is also classified into the “optimistic” approaches (in contrast to pessimistic approaches which utilize locking)
On Intels x86 architecture, the atomic instruction is implemented under the mnemoic LOCK CMPXCHG (see https://c9x.me/x86/html/file_module_x86_id_41.html).
Benchmarking the results
Performance-wise, this approach pays of when you have tons of concurrent reads and only few writes.
My Benchmark Test setup:
- AMD Ryzen 9 7900X3D 12-Core Processor
- 64GiB of DDR5 RAM
- 3D V-Cache
Read benchmark:
- 2048 items serial write
- 10,000 go routines
- each reading and checking 10,000 values
- in total 100,000,000 items read in 2.62s on 24 threads
- so 38M reads/sec
Write benchmark:
- 2048 items serial write
- 1,000 go routines
- each doing 4 passes
- each pass is 10,000 reads and one write
- in total 4,000 reads in 1.14s on 24 thread (during a heavvy read load)
- so 3,5K writes/sec (while rebuilding a 2,048 item list and having 10,000 reads between each write)
carli@launix-MS-7C51:~/projekte/NonLockingReadMap$ go test -v === RUN TestCreate --- PASS: TestCreate (0.00s) === RUN TestAll --- PASS: TestAll (0.00s) === RUN TestConcurrentRead --- PASS: TestConcurrentRead (2.62s) === RUN TestConcurrentWrite --- PASS: TestConcurrentWrite (1.14s) PASS ok github.com/launix-de/NonLockingReadMap 3.758s
Where is it used?
https://github.com/launix-de/memcp
In MemCP, our columnar in-memory database, there are some schema metadata that see a massive parallel access while they are written very seldom (only a few times every month or year). I am talking about:
- The list of databases
- The list of tables in a database
- The list of columns in a table
Before the use of NonLockingReadMap, every reading from the table list or the column data (so basically every time a SQL query is started), the metadata had to be locked with a read-lock (sync.RWMutex).
Of course, we could also use other threadsafe data structures like linked lists for these data, but just imagine how slow they become once there are lots of columns/tables/databases.
Comments are closed